

Part 1: Corpus Linguistics
What is corpus linguistics?
Corpus linguistics is a field which focuses upon a set of procedures, or methods, for studying language. We can take a corpus-based approach to many areas of linguistics. Importantly, the development of corpus linguistics has also spawned new theories of language – theories which draw their inspiration from attested language use and the findings drawn from it.
But corpus linguistics is not a monolithic, consensually agreed set of methods and procedures. It is in fact a heterogeneous field – although there are some basic generalisations that we can make.
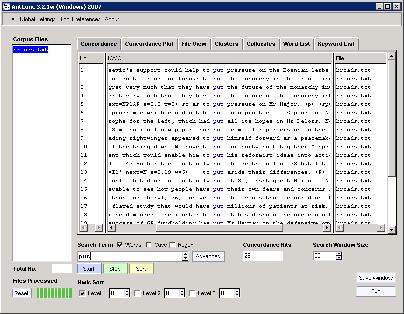
A concordance in the AntConc tool
The main features of corpus linguistics
Research in corpus linguistics deals with some set of machine-readable texts which is deemed an appropriate basis on which to study a particular research questions. The set of texts or corpus is usually of a size which defies analysis by hand and eye alone within any reasonable timeframe. For this reason, corpora are invariably exploited using software search tools. Concordancers allow users to look at words in context. Other tools allow the production of frequency data, for example a word frequency list, which lists all words appearing in a corpus and specifies how many times each one occurs in that corpus. Concordances and frequency data exemplify respectively the two forms of analysis, namely qualitative and quantitative, that are equally important to corpus linguistics.
Different types of corpus study
The following features effectively distinguish different types of studies in corpus linguistics:
- Mode of communication;
- Corpus-based versus corpus-driven linguistics;
- Data collection regimes;
- The use of annotated versus unannotated corpora;
- Multilingual versus monolingual corpora.
This page was last modified on Thursday 26 May 2011 at 3:49 am.