

Annotated versus unannotated corpora
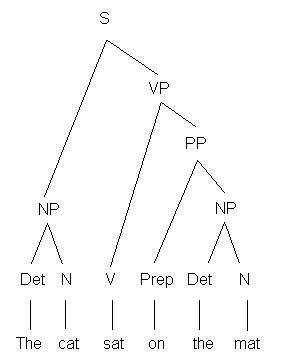
The tree diagram – a commonplace of (corpus) linguistics!
What is corpus annotation?
Linguistic analyses encoded in the corpus data itself are usually called corpus annotation. For example, we may wish to annotate a corpus to show parts of speech, assigning to each word a grammatical category label. So when we see the word talk in the sentence I heard John's talk and it was the same old thing, we would assign it the category noun in that context. This would often be done using some mnemonic code or tag such as N.
While the phrase corpus annotation may be unfamiliar, the basic operation it describes is not – it is just like the analyses of data that have been done using hand, eye, and pen for decades. For example, in Chomsky (1965), 24 invented sentences are analysed; in the parsed version of LOB, a million words are annotated with parse trees. So corpus annotation is largely the process of recording common analysis in a systematic and accessible form.
Annotating data: how to get started
If you are interested in experimenting with automatic annotation for yourself, there are online systems that will allow you to try this out without having to install any software on your own computer.
You can try out grammatical tagging of a small-to-medium text using the web-interface to the CLAWS tagger (below). This tagger, created by UCREL at Lancaster University, is the software that was used to tag the BNC. It can be set to use either of two tagsets, the standard C7 and the less-complex C5.
A more complex form of grammatical annotation is parsing. One easy way to try out parsing is to use the online Stanford Parser. This program does two different types of parsing – dependency parsing and constituency parsing – and is also openly available to download and use on your own computer.
A combination tool that part-of-speech tags text but also dependency-parses it aqnd lemmatises it is the Constraint Grammar system. You can try out Constraint Grammar-based taggers and parsers for English on the web here or here.
This page was last modified on Monday 31 October 2011 at 5:20 am.