

How concordances are displayed
Below are images of screenshots from four popular concordancers, with some short comments. Click on each image to see it at full size.
WordSmith
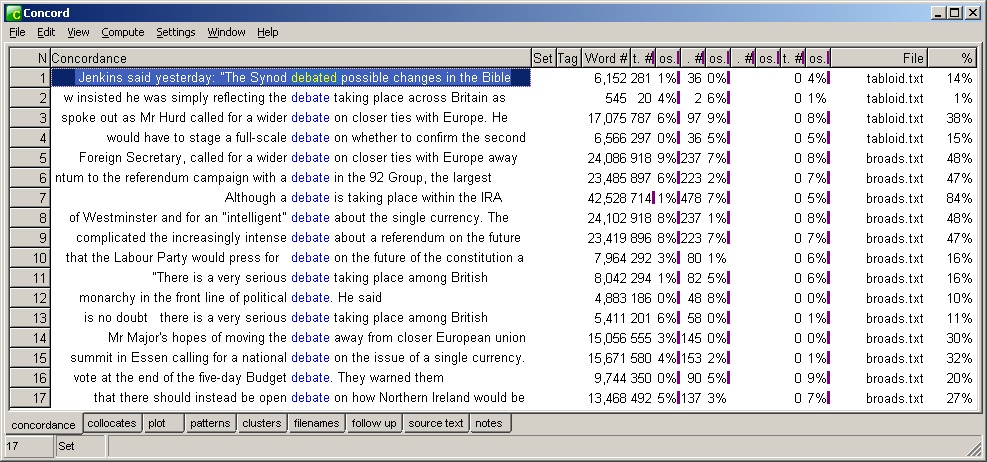
WordSmith (or, more properly, WordSmith Tools), written by Mike Scott, is perhaps the most widely-used third-generation concordancer. It has been through several versions, all of which look a little different: here is a screenshot of a concordance in version 5.
Across the bottom of the Concord tool are controls for performing further analysis of a concordance; other functions, such as frequency lists and keywords, are available through other tool windows.
Find out more about WordSmith here.
AntConc
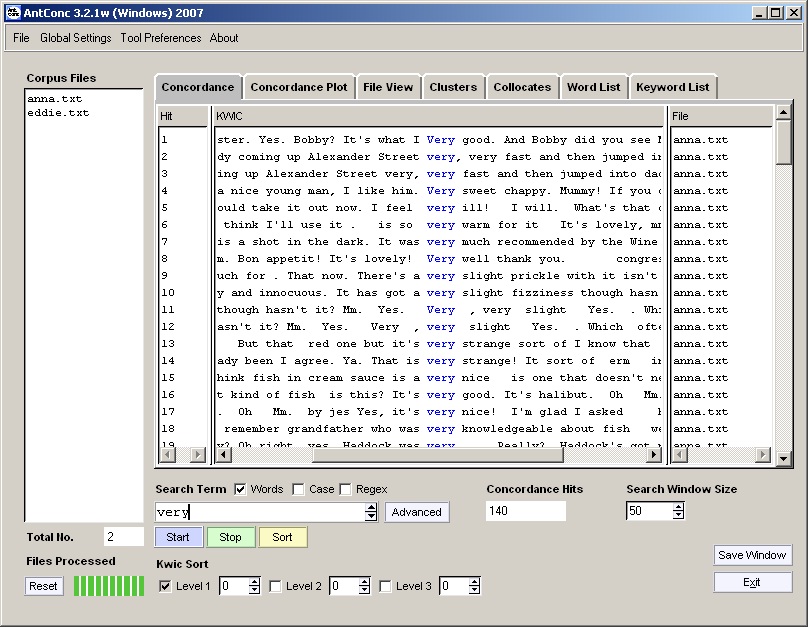
AntConc, written by Laurence Anthony, has approximately the same set of functions as WordSmith, but a different style of user interface.
Find out more about AntConc here.
Corpus.byu.edu
By contrast to WordSmith and AntConc, Mark Davies' corpus.byu.edu system is a fourth-generation> concordancer. Instead of an application that runs locally on your desktop computer, it is a web-based service accessed via a browser.
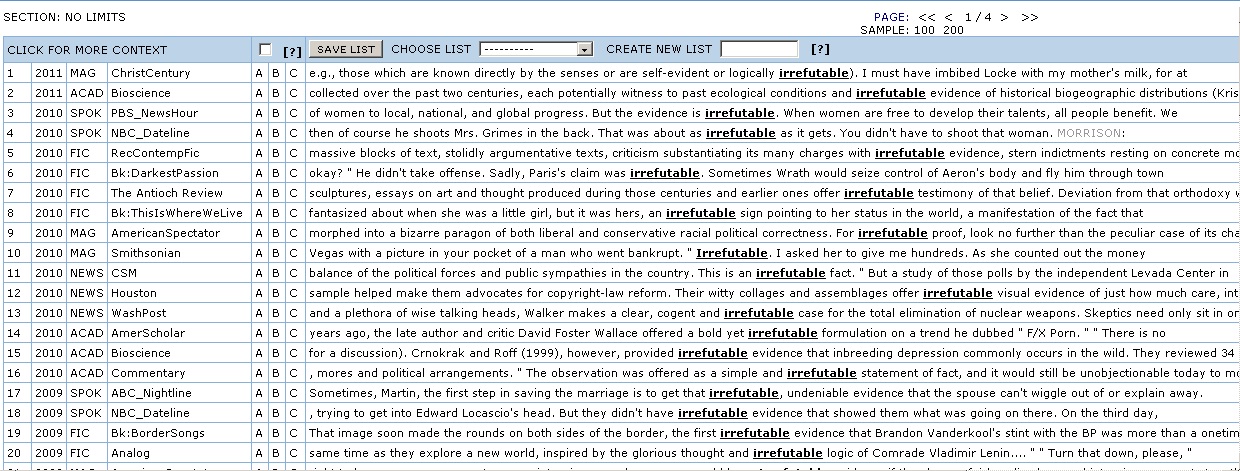
Unlike a desktop concordance tool, a web-based system knows what corpora it will be used to analyse — a set of preloaded datasets set up by the website maintainers. This means it will usually have access to a rich database of information about the corpus and each text it contains, which can appear in the concordance.
The corpus.byu.edu system contains several corpora, most notably, the Corpus of Contemporary American English (COCA), its companion the Corpus of Historical American English (COHA), as the British National Corpus, as well as corpora of Spanish and Portuguese.
You can see some of the metadata for COCA displayed alongside the concordance below from the corpus.byu.edu system (on the left).
Find out more about the corpus.byu.edu datasets here; sign up to use the system here.
CQP
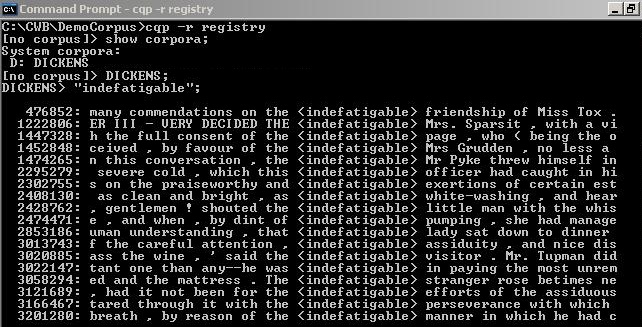
The Corpus Query Processor or CQP is part of Corpus Workbench. It is an example of a concordancer that must be used from a command-line, as you can see in the screenshot below. As such, it is not as user-friendly as any of the three concordancers mentioned above:
Because CQP is not very user-friendly, it is usually used as the server-side engine behind a fourth-generation, web-based concordancer. BNCweb is an example of such a system; another is CQPweb, from which the concordance screenshot below is taken. This screenshot illustrates the use of CQPweb with Chinese corpus data from the Lancaster Corpus of Mandarin Chinese — like most third- and fourth-generation systems, CQP and CQPweb can cope with corpora in any writing system.

This page was last modified on Monday 31 October 2011 at 1:39 am.