#LancsBox: Lancaster University corpus toolbox
Materials

#LancsBox v.5: Introduction
This is a recording of a webinar introducing a brand new version of #LancsBox with the Wizard module for automatic creation of research reports.
The video can be downloaded here.
Introduction to corpus statistics
This lecture is an introducton to corpus statistics. It will take you through the basic concepts and principles of statistical thinking including descriptive and inferential statistics, types of frequency, dispersion, statistical tests, effect sizes etc.
The video can be downloaded here.
Principles of data visualization in corpus linguistics
This lecture takes you on a journey into the world of graphs and tables. It discusses ways of efficient data visualisation in corpus linguistics. Think about this question: How would you visualize a corpus?
The video can be downloaded here.
Collocation networks in discourse
This lecture explains the concepts of discourse, collocation and collocation networks and provides examples of the use of collocation networks in corpus-based discourse studies. The lecture also previews some basic features of #LancsBox, which allow building colocation networks on the fly from user-defined corpora and interpreting the meaning of these networks for discourse analysis.
The video can be downloaded here.
Introduction to #LancsBox v.6 handout
Introduction to #LancsBox v.6 answers
Introduction to #LancsBox v.5 handout
Introduction to #LancsBox v.5 answers
Searches in KWIC - handout
Searches in KWIC - answers
Collocations in GraphColl - handout
Collocations in GraphColl - answers
Wordlists, dispersion and keywords in Words - handout
Wordlists, dispersion and keywords in Words - answers
Build your own corpus - handout
- Baker, P. (2016). The shapes of collocation.International Journal of Corpus Linguistics, 21(2), 139-164.
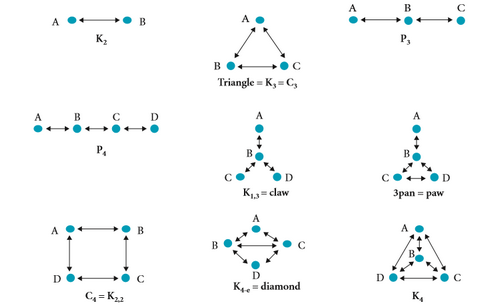 The tool GraphColl (Brezina et al. 2015) allows collocational networks to be identified within corpora, enabling corpus analysis to go beyond two-way collocation. This paper aims to illustrate the types of linguistic relationships that can appear when more than two words are considered, using graph theory to account for the different types of collocational "shapes" that can be formed within GraphColl networks.
[Read more]
The tool GraphColl (Brezina et al. 2015) allows collocational networks to be identified within corpora, enabling corpus analysis to go beyond two-way collocation. This paper aims to illustrate the types of linguistic relationships that can appear when more than two words are considered, using graph theory to account for the different types of collocational "shapes" that can be formed within GraphColl networks.
[Read more] - Brezina, V. (2016). Collocation Networks.In: Baker, P. & Egbert, J. (eds.) Triangulating Methodological Approaches in Corpus Linguistic Research. Routledge: London.
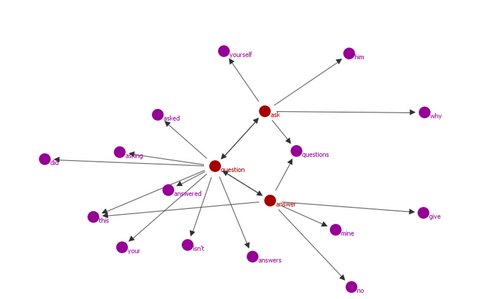 The methodology that is used in this chapter to analyse the complex and multi-faceted linguistics processes which underlie the online communities of practice established around the Q+A sites is that of collocation networks. Collocation networks, a concept originally proposed by Phillips (1983, 1985), are based on a very simple observation. Words in texts and discourse systematically co-occur to create a range of cross-associations that can be visualized as networks of nodes and collocates.
[Read more]
The methodology that is used in this chapter to analyse the complex and multi-faceted linguistics processes which underlie the online communities of practice established around the Q+A sites is that of collocation networks. Collocation networks, a concept originally proposed by Phillips (1983, 1985), are based on a very simple observation. Words in texts and discourse systematically co-occur to create a range of cross-associations that can be visualized as networks of nodes and collocates.
[Read more] - Brezina, V. (2018a) Statistical choices in corpus-based discourse analysis. In: Taylor, Ch. & Marchi, A. (eds.) Corpus approaches to discourse: a critical review. Routledge: London.
- Brezina, V. (2018b) Statistics for corpus linguistics: A practical guide. Cambridge: Cambridge University Press.
- Brezina, V. & Gablasova, D. (2017). The corpus method. In: Culpeper, J, Kerswill, P., Wodak, R., McEnery, T. & Katamba, F. (eds). English Language (2nd edition). Palgrave.
- Brezina, V., McEnery, T. & Wattam, S. (2015). Collocations in context: A new perspective on collocation networks.International Journal of Corpus Linguistics, 20(2), 139-173.
 The idea that text in a particular field of discourse is organized into lexical patterns, which can be visualized as networks of words that collocate with each other, was originally proposed by Phillips (1983). This idea has important theoretical implications for our understanding of the relationship between the lexis and the text and (ultimately) between the text and the discourse community/the mind of the speaker. Although the approaches to date have offered different possibilities for constructing collocation networks, we argue that they have not yet successfully operationalized some of the desired features of such networks.
[Read more]
The idea that text in a particular field of discourse is organized into lexical patterns, which can be visualized as networks of words that collocate with each other, was originally proposed by Phillips (1983). This idea has important theoretical implications for our understanding of the relationship between the lexis and the text and (ultimately) between the text and the discourse community/the mind of the speaker. Although the approaches to date have offered different possibilities for constructing collocation networks, we argue that they have not yet successfully operationalized some of the desired features of such networks.
[Read more] - Brezina, V., & Meyerhoff, M. (2014). Significant or random. A critical review of sociolinguistic generalisations based on large corpora.International Journal of Corpus Linguistics, 19(1), 1-28.
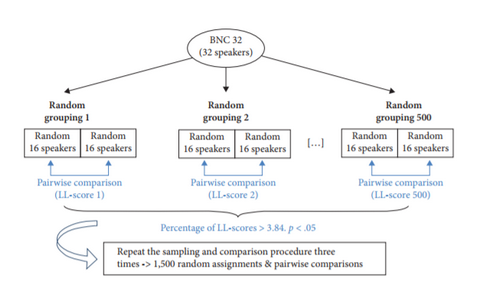 This article offers a critical review of a methodology often employed in corpus-based sociolinguistic studies which make use of aggregate data. It presents evidence which shows that sociolinguistic studies based on aggregate data are in principle unreliable.
[Read more]
This article offers a critical review of a methodology often employed in corpus-based sociolinguistic studies which make use of aggregate data. It presents evidence which shows that sociolinguistic studies based on aggregate data are in principle unreliable.
[Read more] - Gablasova, D., Brezina, V., & McEnery, T. (2017). Collocations in corpus-based language learning research: Identifying, comparing, and interpreting the evidence.Language Learning, 67 (S1), 155–179.
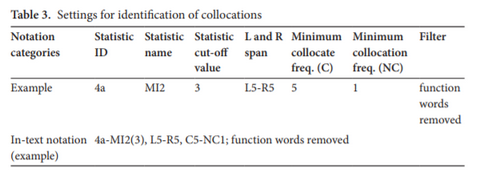
 This article focuses on the use of collocations in language learning research (LLR). Collocations, as units of formulaic language, are becoming prominent in our understanding of language learning and use; however, while the number of corpus-based LLR studies of collocations is growing, there is still a need for a deeper understanding of factors that play a role in establishing that two words in a corpus can be considered to be collocates.
[Read more]
This article focuses on the use of collocations in language learning research (LLR). Collocations, as units of formulaic language, are becoming prominent in our understanding of language learning and use; however, while the number of corpus-based LLR studies of collocations is growing, there is still a need for a deeper understanding of factors that play a role in establishing that two words in a corpus can be considered to be collocates.
[Read more] - Gablasova, D., Brezina, V., & McEnery, T. (2017). Exploring learner language through corpora: comparing and interpreting corpus frequency information.Language Learning, 67 (S1), 130–154.
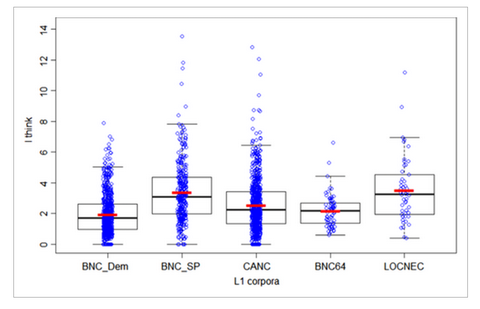 This article contributes to the debate about the appropriate use of corpus data in language learning research. It focuses on frequencies of linguistic features in language use and their comparison across corpora.
[Read more]
This article contributes to the debate about the appropriate use of corpus data in language learning research. It focuses on frequencies of linguistic features in language use and their comparison across corpora.
[Read more]