#LancsBox: Lancaster University corpus toolbox
Introduction
What is #LancsBox?
#LancsBox is a new-generation software package for the analysis of language data and corpora developed at■ Leading research in corpus linguistics.
■ 2015 Queen's Aniversary Prize.
■ More info.
New version of #LancsBox, #LancsBox X,is now available with full XML support and the ability to search very large corpora such as the BNC2014.
Main features of #LancsBox:
- Works with your own data or existing corporaCurrently distributed with:.
■ Brown, LCMC, LOB, Newsbooks, Shakespeare and VULC - Can be used by linguists, language teachers, historians, sociologists, educators and anyone interested in language.
- Visualizes language data.
- Analyses data in any language Morphological annotation available for:. Find out more details about language support.
■ Arabic, Catalan, Czech, Dutch, English, Finish, German, Italian, Latin, Mongolian, Portugese, Romanian, Russian, Slovak, Spanish and Swahili. - Automatically annotates data for part-of-speech#LancsBox includes TreeTagger.
■ Automatically_RB annotates_VBZ data_NNS for_IN part-of-speech_NN - Works with any major operating system (Windows, Mac, Linux).
How to cite #LancsBox?
Brezina, V., Weill-Tessier, P., & McEnery, A. (2020). #LancsBox v. 5.x. [software]. Available at: http://corpora.lancs.ac.uk/lancsbox.
Brezina, V., Timperley, M., & McEnery, T. (2018). #LancsBox v. 4.x [software]. Available at: http://corpora.lancs.ac.uk/lancsbox.
Brezina, V., McEnery, T., & Wattam, S. (2015). Collocations in context: A new perspective on collocation networks. International Journal of Corpus Linguistics, 20(2), 139-173.
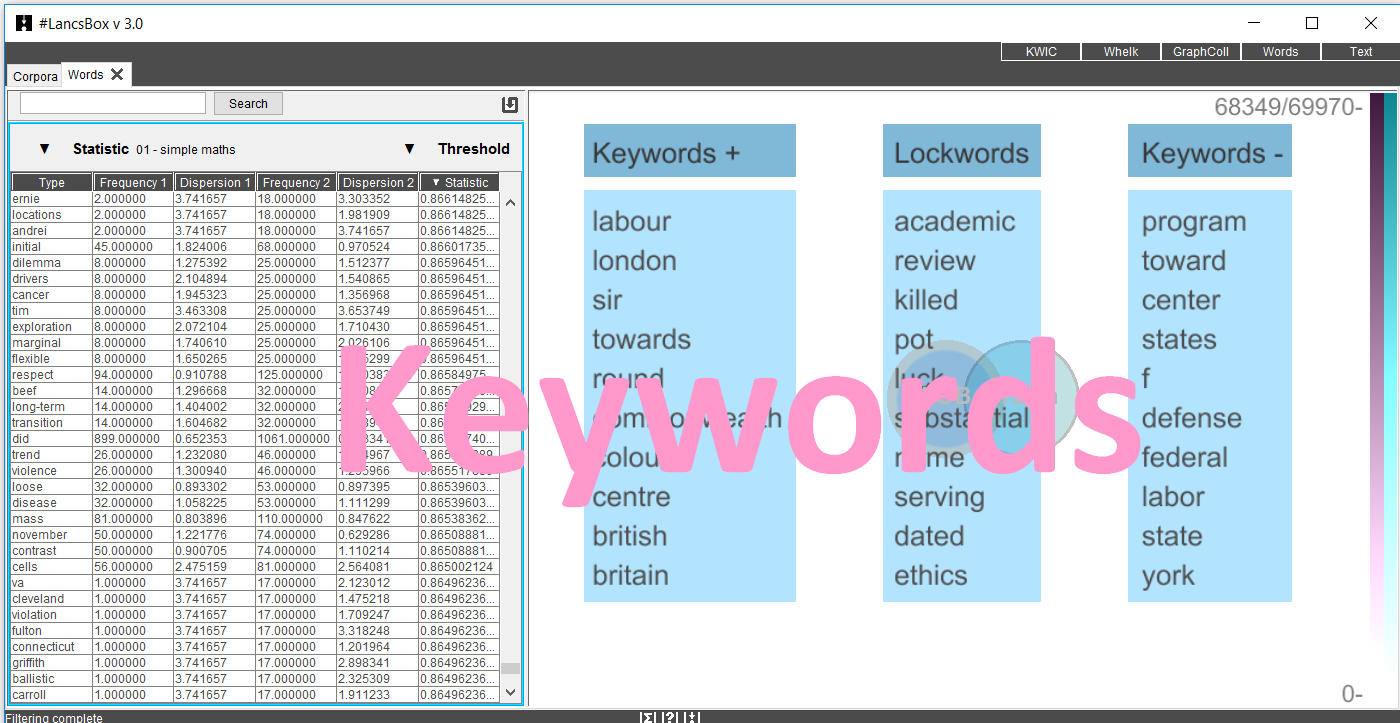
How does #LancsBox work?
#LancsBox is very easy to use.



#LancsBox team
Development team: Vaclav Brezina (Project Lead), William Platt (Developer) and Tony McEnery (Adviser).
Teaching materials coordinator: Dana Gablasova
Student helpers: Grace Edge (2018 SPRINT internship), (Samuel Armstrong, David Ellis (both 2017 SPRINT internship)
Former collaborators: Richard Easty, Matt Timperley (up to #LancsBox v. 4.x), Steve Wattam (GraphColl, v. 1)
Other collaborators: Zoe Broisson, Sophiko Daraselia (University of Leeds), Michael Gauthier (Université Lyon), Lukasz Grabowski, Sulene Pilon (University of Pretoria), Prihantoro (Lancaster University), Caroline Rossi (Université Grenoble Alpes)
We are looking for collaborators to help us develop #LancsBox support in